|
|

楼主 |
发表于 2007-5-28 12:53:04
|
显示全部楼层
|
基礎から理解するデータベースのしくみ(5)
SQL文はどのように実行されるのか(4)

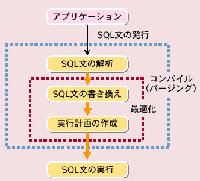
図7●インデックスを作成したほうがよい場合としないほうがよい場合の例
[画像のクリックで拡大表示] |
インデックスの作り過ぎに注意 SQL文を実行する際のパフォーマンスに大きな影響を及ぼすものとして,もう一つ,インデックスがあります。インデックスについては,どう定義すべきかというデータベース設計上の問題と,インデックスを有効に使うためのSQL文をどう書くべきかというコーディング上の問題があります。
ここではテーブル設計上の問題を主に取り上げます。SQL文のコーディングについては囲み記事「SQL文を最速にする11のポイント」を参照してください。
インデックスは,テーブルの検索速度を向上させるためのものです。それぞれのSQL文に対して最適なインデックスを定義するのが理想的ですが,実際にはある程度限られたインデックスで,必要なパフォーマンス要件を満たすようにインデックスを定義する必要があります。加えて,どんなSQL文が実際に発行されるのかがあらかじめわかっていない場合は,適当な想定に基づいてインデックスを定義しておかなくてはなりません。
定義するインデックスの数は,参照のみ行うSQL文であれば論理的にはいくら多くてもかまいません。しかし実際には,SQL文自体は参照しているだけであっても,データのロードやインポートなどの準備過程が必ず発生します。そのため現実には,インデックスの数を制限する必要が生じます。一般に情報系システムやマスター・テーブルのような参照のみのテーブルの場合でも,インデックスの数は6~7個以内を目安とするのが普通です。
インデックスを作成すると検索時間は短縮できますが,データの挿入,削除,更新が遅くなることには注意しておかなければなりません。レコードに対して行う処理以外に,インデックスに対して処理を行う必要があるからです。更新が頻繁に発生するオンライン処理系でデータベースを使用するのであれば,テーブルの更新に伴うインデックス更新の負荷を考慮して,インデックスは2~3個以内にしておくのが良いでしょう。
むやみにインデックスを定義すると,効果がないどころか,有害になることもあります。インデックスを定義するかどうかは処理の内容と頻度を考慮して決めなくてはなりません。インデックスを作成したほうがよい場合と,作成しないほうがよい場合について,(図7[拡大表示])にまとめておきましたので,参考にしてください。
SQL文を最速にする11のポイント たとえ最終的な結果が同じでも,SQL文は書き方一つでパフォーマンスがずいぶんと変わってきます。ここでは,速いSQL文を記述するためのポイントや注意点をいくつか紹介しておきましょう。
●WHEREの左辺で算術演算子や関数を使わない WHERE句の左辺に算術演算や関数を指定すると,インデックスが使われません。例えば,
SELECT NAME FROM CUSTOMERS
WHERE SAL - TAX > 1000とすると,たとえSALフィールドにインデックスが定義されていてもテーブル全体を走査してしまいます。こうした場合は,
SELECT NAME FROM CUSTOMERS
WHERE SAL > TAX + 1000のように記述すれば良いでしょう。
●「後方一致」検索はなるべく避ける インデックスが付加されているフィールドであっても,LIKE '%AAA' のような「後方一致」を指定すると,インデックスを検索せずにデータ部の全表走査が行われます。したがって「後方一致」の使用はなるべく避けるようにしましょう。どうしても必要であるなら,
・何らかの,少量まで絞り込める条件とAND条件で組み合わせる
・複数のフィールドに分割し,少しでも前方・完全一致できる範囲を広げる
といった方法を検討して下さい。
●IS NULL,IS NOT NULLを単独で使わない 条件を表すWHERE句にIS NULL/IS NOTNULLを指定したときは,インデックスを定義したフィールドであっても,全表走査が行われます。したがって,これらの条件を指定するときは,単独で指定するのではなく,何らかのかなり絞り込める条件を合わせて指定してください。例えば,問い合わせの結果を変更せずに「B =10」の条件を付加できるなら
…WHERE A IS NULLとする代わりに
…WHERE A IS NULL AND B = 10とします。
●SELECT文で「*」を使わない レコード長が長いときや,フィールド数が多いときには,すべてのフィールドを表す「*」を指定するのはできるだけ避けて,使用するフィールドだけを指定するようにします。「*」を指定すると,参照系のSQL文では,すべてのフィールドを繰り返してコピーするため,リソースを無駄に使うことになります。最低限度必要なフィールドだけを指定するのが基本です。
●ORはある程度絞り込んでから使う 論理演算子ORを使用した場合,一応インデックスが使用されるものの,個々の条件が抽出する件数が少ない(数%程度)状態でないと,あまり効果がありません。
●DISTINCTの代りにEXISTSを使う SELECT文にDISTINCT*Aを指定すると処理に非常に時間がかかります。DISTINCTを使用するのは極力避けましょう。DISTINCTと同等の結果を得ることのできるSQL文にEXISTSがあります。例えば,
SELECT DISTINCT a.ID1, a.NAME1 FROM
TABLE1 a, TABLE2 b WHERE a.ID1 = b.ID2のSQL文は,副問い合わせの条件としてEXISTSを指定して
SELECT a.ID1, a.NAME1 FROM TABLE1 a
WHERE EXISTS ( SELECT 'X' FROM
TABLE2 b WHERE a.ID1 = b.ID2)と書き換えることができます。同様に,NOT INからNOT EXISTSに代替することによってパフォーマンスが向上することもあるので,これも検討してみてください。
●GROUP BY,ORDER BY,HAVINGは注意する GROUP BY句,ORDER BY句,HAVING句は,余分なディスク入出力が発生したりディスク領域を使うので,自分もしくはほかのプログラムのパフォーマンスに悪影響を及ぼします。このことを念頭において,使わずに済むならなるべく使わないようにしましょう。
●演算子の組み合わせで速度が変わる 検索条件に,「>」「<」「=」をANDで組み合わせるときは,指定の仕方によってインデックスの使われ方が異なります。等号と不等号の組み合わせは,等号のみインデックスが使われます。例えば,
SELECT NAME FROM CUSTOMERS
WHERE JOB = 'MANAGER'
AND SAL > 1000とすると,「JOB = 'MANAGER'」にはインデックスが使われますが,「SAL > 1000」には使われません。また,不等号同士の組み合わせでは,先に指定した条件だけにインデックスが使われます。つまり
SELECT NAME FROM CUSTOMERS
WHERE TAX > 100
AND SAL > 1000のSQL文では,RDBMSは「TAX > 100」だけにインデックスを使い「SAL > 1000」には使いません。
●テーブルの別名を利用する テーブルに別名をつけて,フィールド名にはその別名をつけると,SQL文の解析処理を減らすことができます。例えば,
SELECT ID, NAME FROM CUSTOMERS
WHERE SAL < 1000
よりも,
SELECT a.ID, a.NAME FROM CUSTOMERS a
WHERE SAL < 1000
のほうが高速になります。●SQL文の表現を統一する 本文中で述べたように,RDBMSは実行計画をキャッシュに保存しておいて再利用します。ところが,SQL文に定数を直接記述してしまうと,RDBMSは定数値だけが異なるSQL文を別のものと解釈するため,再利用されません*B。バインド変数を使用して,できる限りSQL文を統一するようにします。また,文字の大小や記述の仕方なども統一しておかないと別のSQL文だと認識されてしまうので,気を付けてください。
●SQL文を簡潔に記述する SQL文はなるべく簡潔に記述するようにします。そうすることで,SQL文の処理時間を短縮することができます。 |
|


 发表于 2007-5-28 11:06:25
发表于 2007-5-28 11:06:25
 提升卡
提升卡 变色卡
变色卡